The Trouble with Tor
The Tor Project makes a browser that allows anyone to surf the Internet anonymously. Tor stands for "the Onion router" and that describes how the service works. Traffic is routed through a number of relays run across the Internet where each relay only knows the next hop (because each hop is enclosed in a cryptographic envelope), not the ultimate destination, until the traffic gets to the final exit node which connects to the website — like peeling the layers of an onion.

Think of it like a black box: traffic goes into the box, is bounced around between a random set of relays, and ultimately comes out to connect to the requested site. Anonymity is assured because anyone monitoring the network would have a difficult time tying the individuals making the requests going into the black box with the requests coming out.
Importance and Challenges of Anonymity
Anonymity online is important for a number of reasons we at CloudFlare think are important. For instance, Tor is instrumental in ensuring that individuals living in repressive regimes can access information that may otherwise be blocked or illegal. We offer our service freely through Project Galileo to protect politically and artistically important organizations and journalists against attacks that would otherwise censor their work.
On the other hand, anonymity is also something that provides value to online attackers. Based on data across the CloudFlare network, 94% of requests that we see across the Tor network are per se malicious. That doesn’t mean they are visiting controversial content, but instead that they are automated requests designed to harm our customers. A large percentage of the comment spam, vulnerability scanning, ad click fraud, content scraping, and login scanning comes via the Tor network. To give you some sense, based on data from Project Honey Pot, 18% of global email spam, or approximately 6.5 trillion unwanted messages per year, begin with an automated bot harvesting email addresses via the Tor network.
![]() CC BY 3.0 logo from the Tor Project
CC BY 3.0 logo from the Tor Project
At CloudFlare we've not explicitly treated traffic from Tor any differently, however users of the Tor browser have been more likely to have their browsing experience interrupted by CAPTCHAs or other restrictions. This is because, like all IP addresses that connect to our network, we check the requests that they make and assign a threat score to the IP. Unfortunately, since such a high percentage of requests that are coming from the Tor network are malicious, the IPs of the Tor exit nodes often have a very high threat score.
With most browsers, we can use the reputation of the browser from other requests it’s made across our network to override the bad reputation of the IP address connecting to our network. For instance, if you visit a coffee shop that is only used by hackers, the IP of the coffee shop's WiFi may have a bad reputation. But, if we've seen your browser behave elsewhere on the Internet acting like a regular web surfer and not a hacker, then we can use your browser’s good reputation to override the bad reputation of the hacker coffee shop's IP.
The design of the Tor browser intentionally makes building a reputation for an individual browser very difficult. And that's a good thing. The promise of Tor is anonymity. Tracking a browser's behavior across requests would sacrifice that anonymity. So, while we could probably do things using super cookies or other techniques to try to get around Tor's anonymity protections, we think that would be creepy and choose not to because we believe that anonymity online is important. Unfortunately, that then means all we can rely on when a request connects to our network is the reputation of the IP and the contents of the request itself.

Security, Anonymity, Convenience: Pick Any Two
The situation reminds me of those signs you see in diners: "fast, good, cheap (pick any two)." In our case, the three competing interests are security, anonymity, and convenience. Unfortunately, you can’t provide all three so the question is: what do you sacrifice?
Our customers sign up for CloudFlare to protect them from online attacks, so we can't sacrifice security. We also believe anonymity is critical, having witnessed first hand how repressive regimes use control of the network to restrict access to content. So that leaves sacrificing a bit of convenience for users of the Tor browser.
CAPTCHAs
Fundamentally, the challenge we have is telling automated malicious traffic sent via Tor from legitimate human users. To do that, when a visitor is coming from a Tor exit node with a poor reputation, we will often use some sort of CAPTCHA. CAPTCHA stands for "Completely Automated Public Turing test to tell Computers and Humans Apart" — which is exactly what we're trying to do.
CAPTCHAs have become known for squiggly letters that you type into a box, but they could be anything that is relatively easy for real humans but hard for automated systems. Building a CAPTCHA is an extremely difficult computer science problem. We currently use Google's reCAPTCHA and recently switched from the older ‘squiggly letters’ version to the latest revision to make life easier for humans and harder for bots. We're not particularly happy with reCAPTCHA, but we haven't found an alternative that is better and can operate at our scale.

To make sure our team understood what a pain CAPTCHAs could be, I blacklisted all the IP addresses used in CloudFlare's office so our employees would need to pass a CAPTCHA every time they wanted to visit any of our customers' sites. This dogfooding experience caused us to make some changes to make the CAPTCHAs more convenient, including convincing Google to allow us to use their new version of reCAPTCHA. It's better, but it's still less convenient than using a non-Tor browser.
We also made a change based on the experience of having to pass CAPTCHAs ourselves that treated all Tor exit IPs as part of a cluster, so if you passed a CAPTCHA for one you wouldn’t have to pass one again if your circuit changed. Over the twelve months, we’ve made incremental progress toward our goal of finding some way to provide a CAPTCHA that distinguishes automated and human traffic without being too inconvenient for the humans — but we’re not there yet.
Since the list of Tor exit nodes is public we’ve open sourced our tools used to examine the reputation and life of exit nodes. torhoney matches Tor exit nodes and information from Project Honey Pot to see which nodes are most misused and torexit can be used to determine the longevity of Tor exit nodes. We used it to tune our download of the Tor exit node list to ensure that we were up to date.
Using torhoney we produced the following chart showing the percentage of Tor exit nodes that were listed by Project Honey Pot as a comment spammer over the last year.
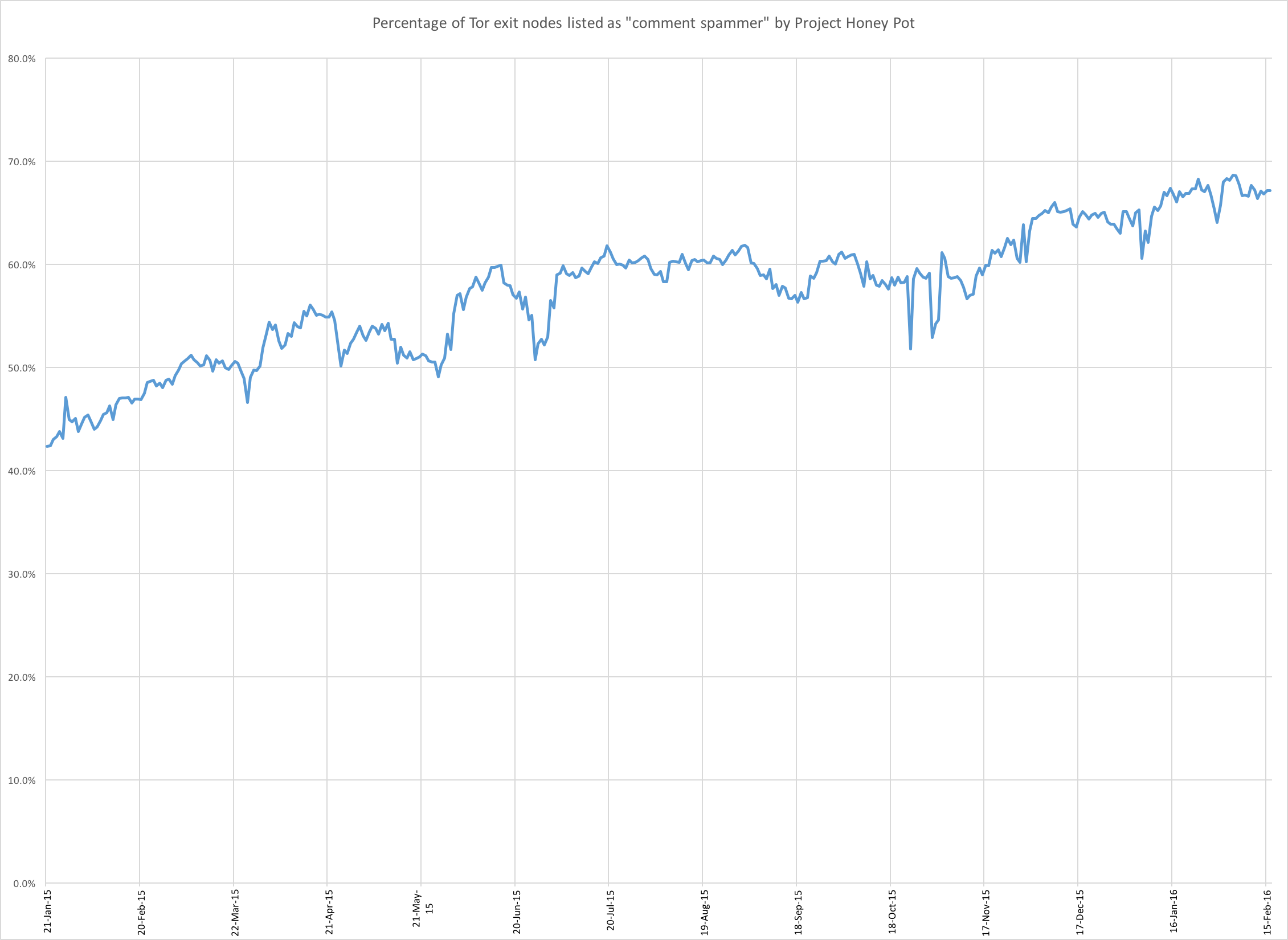
As you can see the percentage is progressing steadily upwards.
Using torexit we produced the following diagram. Each column represents an individual Tor exit node and each row is a 15 minute interval. White means that the exit node was not in the exit node list during that 15 minute interval.

As you can see most exit nodes are stable and work continuously. One the right are nodes that disappeared at some point and the slanting block on nodes on the left appear for 24 hours and then disappear (perhaps because of DHCP leases).
There are a number of problems with our current implementation and we are not satisfied with it. One is that Google themselves see significant malicious traffic from Tor so the reCAPTCHA challenges they present to Tor users are among the hardest. We're talking with Google about how we can overcome that. Another problem is that you have to pass a CAPTCHA for each site you visit. Unfortunately, to solve that, we'd need to track Tor users across sites which would sacrifice Tor’s anonymity so we’ve deemed it unacceptable.
Imperfect Solutions
So what are potential solutions? One suggestion has been that we treat GET requests for static content differently than we do more risky requests like POSTs. We actually already do treat more dangerous requests differently than less risky requests. The problem is Tor exit nodes often have very bad reputations due to all the malicious requests they send, and you can do a lot of harm just with GETs. Content scraping, ad click fraud, and vulnerability scanning are all threats our customers ask us to protect them from and all only take GET requests.
Another suggestion is that we allow our customers to whitelist Tor exit nodes. We resisted this for quite some time, but perhaps not for the reason you'd expect. If we provide a way to treat Tor differently by applying a rule to whitelist the network's IPs we couldn't think of a justifiable reason to not also provide a way to blacklist the network as well. And, while Tor users think it's a no-brainer that sites would whitelist their traffic, if you talk actually with site owners the majority would prefer to just block Tor traffic entirely. In fact, when we looked at our customer base, we found that far more had manually entered Tor exit node IPs to block them than to whitelist them. We didn’t want to make blacklisting easier because, again, we believe there’s value in the anonymous web surfing that Tor offers.


We relented a few weeks ago and allowed our customers to specify rules that apply to traffic from the Tor network, but we came up with a compromise to prevent the damage from full blacklisting. We now allow our customers to treat Tor the same way as we do traffic from a country (country code “T1” to be specific). Just like with countries, traffic can be whitelisted by anyone, but we don't allow our self-service customers to fully blacklist traffic. Customers can force traffic to see a CAPTCHA, but they can't block traffic entirely. However, the choice of how to handle Tor is now in the hands of individual site owners.
Long Term Solutions
The long term the solution has to be something that allows automated, malicious traffic to be distinguished from non-automated traffic coming through the Tor network. We see two viable ways of doing that, but we need help from the Tor Project to implement either of them.
The first would be to make it easy, or maybe even automatic, for CloudFlare customers to create a .onion version of their sites. These .onion sites are only accessible via the Tor network and therefore less likely to be targeted by automated attacks. This was Facebook’s solution when faced with the same problem. We think it’s elegant.
The problem is generating SSL certificates to encrypt traffic to the .onion sites. Tor uses hashes generated with the weak SHA-1 algorithm to generate .onion addresses and then only uses 80 bits of the 160 bits from the hash to generate the address, making them even weaker. This creates a significant security risk if you automatically generate SSL certificates. An attacker could generate a site that collides with the 80-bit .onion address and get a certificate that could be used to intercept encrypted traffic.
Because of this risk, the CA/B Forum, which regulates the issuance of SSL certificates, requires certificates for .onion addresses to be EV certificates. EV certificates require extended validation procedures which limit the risk they can be issued to a malicious party. Unfortunately, those same procedures prevent EV certificates from being issued automatically and make them prohibitively expensive for us to automatically create for all our customers.
The solution is for the Tor Project to support a stronger hashing algorithm, such as SHA256, for .onion addresses. With that in place, we believe the CA/B Forum would be open to discussing the automatic issuance of certificates. That would allow us to create .onion sites for our customers, whitelist Tor traffic to the .onion sites, and continue to protect our customers from automated attacks sent via the Tor network targeting their non-.onion sites.
Client-Side CAPTCHAs
Some members of CloudFlare’s team have proposed a solution to the Tor Project that moves the process of distinguishing between automated and human traffic to the Tor browser itself. The Tor browser could allow users to do a sort of proof-of-work problem and then send a cryptographically secure but anonymous token to services like CloudFlare in order to verify that the request is not coming from an automated system.
By moving the proof-of-work test to the client side, the Tor browser could send confirmation to every site visited so that users wouldn’t be asked to prove they are human repeatedly. Providing a way to distinguish a human using Tor from an automated bot would not only benefit traffic to CloudFlare but, if it became a standard, could also make it easier for other organizations that have restricted Tor traffic out of concern for abuse to start allowing verified-human Tor users back on their sites.
This blinded token solution is outlined in this draft.
So What’s Next?
CloudFlare is working to reduce the impact of CAPTCHAs on Tor users without in any compromising their anonymity and without exposing our customers to additional risk. Over the coming weeks and months we will roll out changes designed to make the lives of legitimate Tor Browser users easier while keeping our customers safe.
Our mission is to build a better Internet and that means protecting web sites from harm and ensuring that web users who wish to remain anonymous are able to do so.
We believe that the Internet will be better off if we do so as sites will not find themselves wanting to ban Tor users completely just because of abuse.
As we've done for DDoS attacks we are working to put in place technology that will filter out the bad coming from Tor while allowing the good through and we are happy to work with the Tor Project to make that a reality.