SIDH in Go for quantum-resistant TLS 1.3
The Quantum Threat
 <p>Most of today’s cryptography is designed to be secure against an adversary with enormous amounts of computational power. This means estimating how much work certain computations (such as factoring a number, or finding a discrete logarithm) require, and choosing cryptographic parameters based on our best estimate of how much work would be required to break the system.</p>
<p>Most of today’s cryptography is designed to be secure against an adversary with enormous amounts of computational power. This means estimating how much work certain computations (such as factoring a number, or finding a discrete logarithm) require, and choosing cryptographic parameters based on our best estimate of how much work would be required to break the system.</p>
If it were possible to build a large-scale quantum computer, many of the problems whose difficulty we rely on for security would no longer be difficult to solve. While it remains unknown whether large-scale quantum computers are possible (see this article for a good overview), it's a sufficient risk that there's wide interest in developing quantum-resistant (or post-quantum) cryptography: cryptography that works on ordinary computers we have today, but which is secure against a possible quantum computer.
At Cloudflare, our biggest use of cryptography is TLS, which we use both for serving our customers' websites (all Cloudflare sites get free HTTPS), as well as for internal inter-datacenter communication on our backend.
In the TLS context, we want to create a secure connection between a client and a server. There are basically three cryptographic problems here:
Authenticity: the server needs to prove to the client that it is the real server (and optionally, the client can prove to the server that it's the real client);
Key agreement: the server and client need to agree, over an insecure connection, on a temporary shared secret known only to them;
Symmetric encryption: the server and client need to use their shared secret to encrypt the data they want to send over a secure connection.
Authenticity protects against active attackers, but because quantum computers aren't yet believed to exist, the main risk is a retroactive attack: for instance, a nation-state adversary (let's say, "NSA" for short) could record encrypted traffic, wait to build a quantum computer, and try to decrypt past traffic. Moreover, quantum algorithms seem to give only a small speedup against symmetric encryption, so the "key" problem to solve is #2, quantum-resistant key agreement.
This is an active area of research, both in the design of new cryptosystems and in their implementation and deployment. For instance, last year, Google concluded an experiment using a lattice-based key exchange in Chrome. Lattice-based cryptosystems are an extremely promising family of quantum-resistant algorithms. Their security relies on well-studied computational problems, and they are computationally efficient. However, they have large key sizes and can require extra communication (which can necessitate additional round-trips in protocols like TLS).
Another family of cryptosystems are supersingular isogeny systems, in particular supersingular isogeny Diffie-Hellman (SIDH). In contrast to lattice-based systems, they rely on more exotic computational problems and are much more computationally expensive. However, they have much smaller key sizes and do not require extra communication: SIDH fits perfectly into TLS 1.3's key agreement mechanism.
TLS 1.3 is the latest version of the TLS protocol. This summer, I've been working at Cloudflare on an experiment for a quantum-resistant version of TLS 1.3 using a hybrid key agreement combining X25519 and supersingular isogeny Diffie-Hellman (SIDH). To achieve this, I implemented a TLS 1.3 client in Go (as part of Cloudflare's tls-tris), implemented SIDH in Go for the amd64 architecture, and combined the SIDH implementation with the TLS 1.3 key agreement mechanism to perform a quantum-resistant TLS 1.3 handshake. This extends previous work by Microsoft Research on a SIDH-based key exchange for TLS 1.2, discussed below.
Diffie-Hellman key agreement in TLS 1.3
In the most recent version of TLS, TLS 1.3, the key agreement mechanism (part 2) is cleanly separated from the authentication mechanism (part 1). TLS 1.3 does key agreement using Diffie-Hellman, usually with an elliptic curve group. Before diving into the quantum-resistant version, let's review how Diffie-Hellman (DH) works, and how it works in the context of TLS 1.3.
In Diffie-Hellman, we have two parties, Alice and Bob, wishing to establish a shared secret. They fix an abelian group G of prime order p, written additively, as well as a generator P of G (the basepoint). Alice then selects a uniformly random integer a in the range [0,p]. This determines a multiplication-by-a map, usually denoted [a] : G -> G. Alice computes the [a]P, the image of the basepoint under her map, and sends it to Bob. Similarly, Bob chooses a random integer b in the range [0,p], determining the map [b], computes [b]P, and sends it to Alice. Alice and Bob then agree on a shared secret [ab]P, which Alice computes as [a]([b]P) and Bob computes as [b]([a]P):
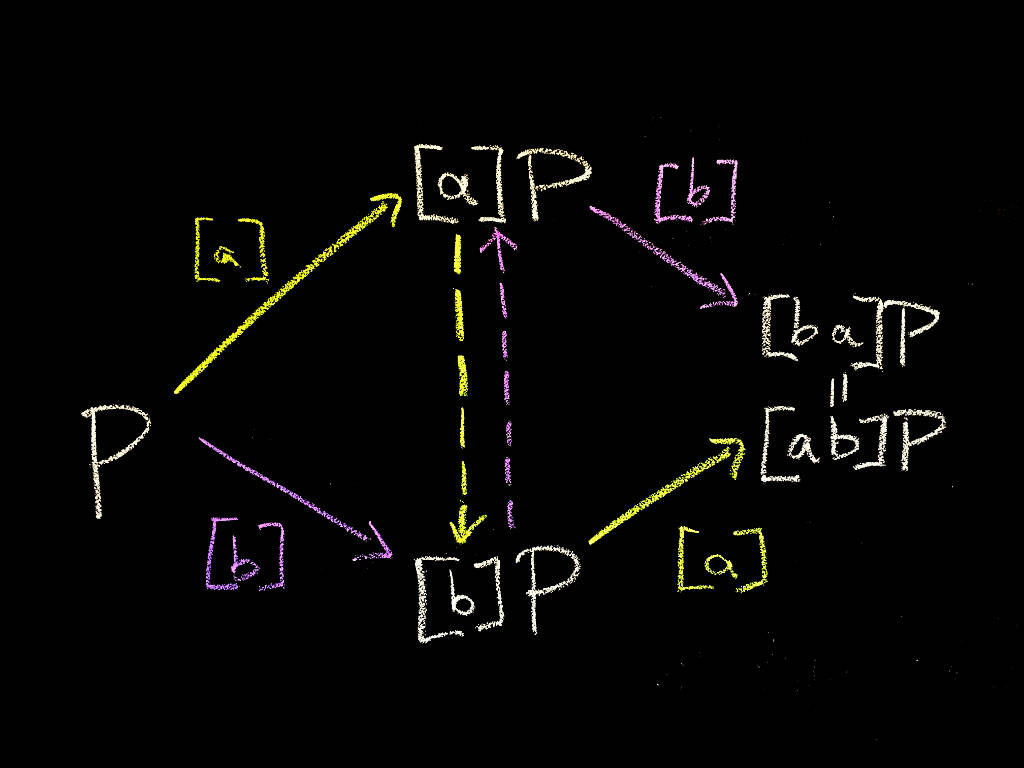
(Here I'm describing the process in terms of maps, in order to show similarity with SIDH later).
In the TLS 1.3 context, this works as follows. A client initiates a connection by sending a TLS ClientHello message, which contains (among other data) a list of DH groups supported by the client, as well as "keyshares" (i.e., the [a]P values) for some (or all) of these groups.
The server selects one of the DH groups supported by both the server and the client. In the happy case, the server selects a group the client provided a keyshare for, and sends back a ServerHello message containing the server's keyshare. From this point on, all handshake messages between the client and server, such as certificates, extensions, etc., are encrypted using a "handshake secret" derived from the keyshares. (In the unhappy case, where the client did not provide an acceptable keyshare, the server asks the client to retry, forcing an extra round-trip).
Application data is later encrypted with a key derived from the handshake secret, as well as other data, so the security of the application data depends on the security of the key agreement. However, all existing DH groups in TLS are vulnerable to quantum algorithms.
Supersingular-isogeny Diffie-Hellman
SIDH, proposed in 2011 by Luca De Feo and David Jao, is a relatively recent proposal for using elliptic curves to build a quantum-resistant Diffie-Hellman scheme.
Roughly speaking, rather than working within a single elliptic curve group, SIDH works within a family of related, "isogenous" elliptic curves.
An isogeny is a map phi : E_1 -> E_2 of elliptic curves which sends the identity element of the source curve E_1 to the identity of the target curve E_2. It turns out that for every isogeny phi: E_1 -> E_2, there's a dual isogeny psi: E_2 -> E_1, so we can say that two curves are isogenous if they're linked by an isogeny.
Now we can consider an isogeny graph, whose edges are isogenies and whose vertices are elliptic curves. Instead of choosing secret multiplication-by-n maps to move around inside one elliptic curve, Alice and Bob choose secret isogenies to move around inside a family of isogenous curves (i.e., they choose a random path through the isogeny graph), and the security of the system is related to the difficulty of computing isogenies between arbitrary curves.
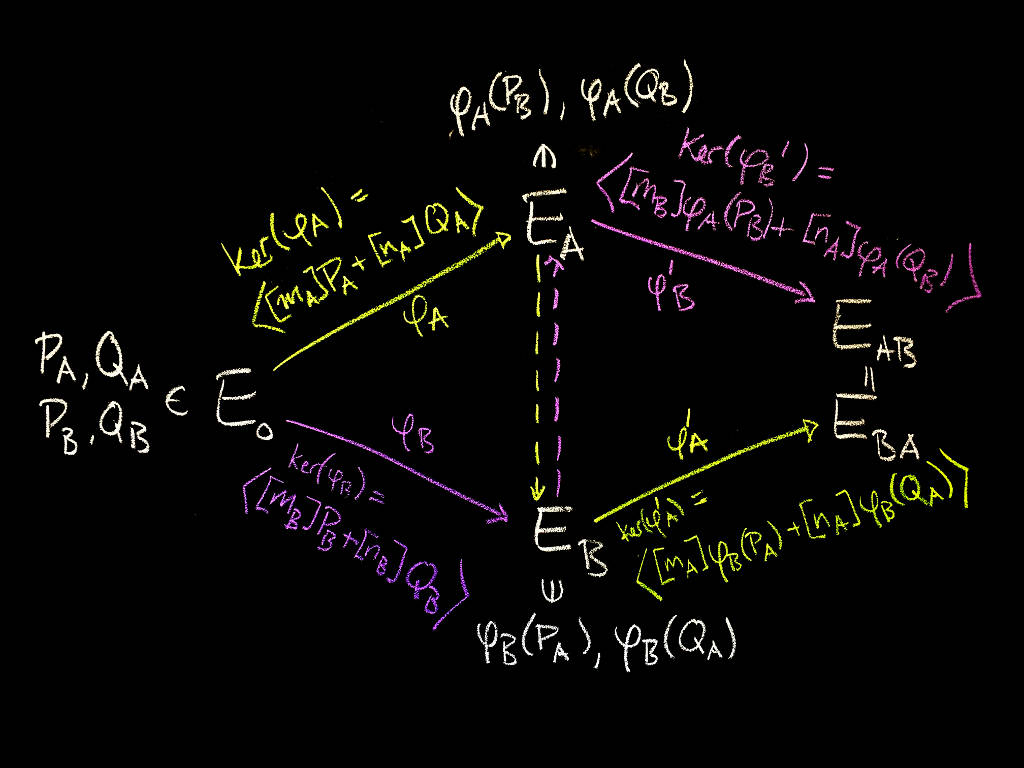
The resulting diagram is slightly more complicated, but structurally similar to the one above:

What exactly is going on here? The starting curve E_0, as well as the points P_A, Q_A, P_B, Q_B, are system parameters.
An isogeny is uniquely determined by its kernel (the subgroup of points on the source curve which the isogeny maps to the identity point of the target curve). To choose an secret isogeny phi_A, Alice chooses secret scalars m_A, n_A, which determine a secret point [m_A]P_A + [n_A]Q_A, which generates the kernel subgroup and hence determines her secret isogeny phi_A. Alice evaluates phi_A at the points P_B, Q_B, and sends E_A, phi_A(P_B), phi_A(Q_B) to Bob, who does the same steps with A and B swapped.
Next, Alice uses E_B, phi_B(P_A), phi_B(Q_A) to construct an isogeny phi'_A with kernel , while Bob uses E_A, phi_A(P_B), phi_A(Q_B) to construct an isogeny phi'_B with kernel .
Now phi'_A maps to the curve E_AB, while phi'_B maps to the curve E_BA. The curves E_AB and E_BA are isomorphic. Since elliptic curves are classified by a number called the j-invariant, j(E_AB) = j(E_BA), and this is the shared secret between Alice and Bob.
A detailed technical explanation of this process can be found in the expansion to the SIDH paper by Luca De Feo, David Jao, and Jérôme Plût (the diagram above is Figure 1 of that paper), and an explanation in terms of rocket ships traveling through supersingular space-time can be found in this article by Luca De Feo. Alternately, there's a recording here of Deirdre Connolly's talk at the February 2017 Cloudflare Crypto Meetup.
In 2016, Craig Costello, Patrick Longa, and Michael Naehrig, at Microsoft Research, published a paper on efficient algorithms for SIDH, applying optimization techniques from high-speed ECC to the original SIDH proposal.
They also published a constant-time, optimized implementation written in C and assembly, and a patch to OpenSSL to create SIDH ciphersuites for TLS 1.2. My Go implementation builds on their work (both algorithms and code), as discussed below.
SIDH key agreement in Go TLS
The SIDH implementation in the p751sidh package has two parts: an outer p751sidh package containing SIDH functionality, and an inner p751toolbox package providing low-level functionality.
Because SIDH is implemented in terms of operations in a large finite field, the performance of the field arithmetic is critical to the performance of the protocol. Unfortunately, this requires writing assembly, because writing high-performance arithmetic is not possible in Go — it's simply not a design goal of the language. (There are a few reasons, most notably that there's no way to directly compute the (128-bit) product of 64-bit integers.)
The code is partially derived from the Microsoft Research implementation mentioned above. In particular, the field arithmetic is ported from the MSR assembly, and the implementation strategy follows their paper. (I experimented with a prototype implementation of field arithmetic using AVX2 and unsaturated limbs, but decided not to use it, since it got similar performance at the cost of less portability and more power use).
The assembly code for the lowest level field arithmetic is oriented around pointers to fixed-size buffers; this is wrapped in a Go API modeled after the big.Int API. To test that the code behaves correctly, I used Go's testing/quick package to write property-based tests, which generate random field elements and compare the results of various operations against the same operations using big.Int.
Curve and isogeny functions are implemented using the Go API, and the outer-level SIDH functions achieve comparable performance as compared to the MSR implementation. In rough benchmarks, the Go implementation appears to be within 2-6% of the MSR implementation. The entire implementation is constant-time.
Concretely, on a T460s, Skylake i7-6600U @2.6GHz1, key generation and shared secret computations take 11-13ms. Note that unlike classic Diffie-Hellman, Alice and Bob's computations are slightly different, so they have different timings.
BenchmarkAliceKeyGen 11,709,778 ns/op
BenchmarkBobKeyGen 13,073,380 ns/op
BenchmarkSharedSecretAlice 11,256,985 ns/op
BenchmarkSharedSecretBob 12,984,817 ns/op
This is much more computationally expensive than a conventional ECDH key agreement, or a lattice-based key agreement. However, from the point of view of latency, this might not be so bad. For example, 12 milliseconds is the round-trip distance between Paris and Amsterdam, and so a key agreement requiring extra communication could easily take longer, even if the computations were less expensive.
Because SIDH is still new and unproven, the TLS integration performs a hybrid key exchange: it sends both an X25519 keyshare and an SIDH keyshare, performs both X25519 and SIDH shared secret computations, and feeds both shared secrets into the TLS key derivation mechanism. This ensures that even if SIDH turns out to be broken, the key agreement is at least as secure as X25519.
The TLS component is implemented as part of tls-tris, Cloudflare's fork of Go's crypto/tls package, which has a partial implementation of TLS 1.3, Draft 18. Because tris didn't support client functionality, I implemented a basic TLS 1.3 client before working on SIDH.
The hybrid key exchange is specified using the group identifier 0xFE24. The 0xFE places it in the private-use reserved codeblock 0xFE00..0xFEFF, since standardizing SIDH would be premature at this time; the number 24 was chosen due to its deep mathematical significance and connection to moonshine.
The entire SIDH integration takes less than 100 lines of code.
Misassembly hazards in Go assembly
The Microsoft Research SIDH implementation provides x64 assembly for field arithmetic, but Go's assembler uses a bespoke syntax derived from Plan 9, so reusing their assembly meant porting it to Go assembly.
When I first did this, the code produced incorrect results, even though all the instructions should have been exactly the same. I was eventually able to find the problem by dissassembling the generated Go binary, and comparing to the original assembly.
The original assembly was roughly of the form
...
sbb r10, rax
movq rax, 0
sbb rax, 0
...
The sbb dst, src instruction is "subtract with borrow"; this instruction reads the carry flag CF and sets dst = dst - (src + CF), CF = 1 if dst < src+CF. So, this code is supposed to set the rax register to 0 if the first subtraction did not underflow, and to 1111...11 if it did. (This value is used later in the computation as a mask). However, writing
...
SBBQ AX, R10
MOVQ $0, AX
SBBQ $0, AX
...
does not have the same result. The reason is that the Go assembler misassembles the MOVQ $0, AX instruction to xor eax, eax. This instruction has a shorter encoding. Unfortunately, it also has different behaviour: it clears the carry flag, breaking the program.
The reason this happens is that MOV in Go assembly is declared to be a "pseudoinstruction", which does not necessarily correspond to a literal mov instruction. Unfortunately, there's no specification of which instructions are pseudoinstructions, and what their behaviour is — MOV in Go assembly is defined to clobber flags, but this isn't documented outside of compiler internals.
To work around this issue, we can drop literal bytes into the instruction stream. In this case, we write
#define ZERO_AX_WITHOUT_CLOBBERING_FLAGS BYTE $0xB8; BYTE $0; BYTE $0; BYTE $0; BYTE $0;
...
SBBQ AX, R10
ZERO_AX_WITHOUT_CLOBBERING_FLAGS
SBBQ $0, AX
to insert the bytes encoding the mov eax, 0 instruction, which leaves the carry flag intact.
Source Code
This implementation is still experimental, and should not be used in production without review. The computational cost of SIDH may keep it from being practical for short-lived client connections (at least in the near term). However, it may be suitable for long-lived connections, such as inter-datacenter connections, where the cost of the handshake is amortized over the length of the connection.
To find out more, the SIDH implementation can be found on GitHub as the p751sidh package. The TLS integration can be found on my hdevalence/sidh branch of tls-tris.
Thanks to Craig Costello, Diego Aranha, Deirdre Connolly, Nick Sullivan, Watson Ladd, Filippo Valsorda, and George Tankersley for their advice, comments, and discussions.
Unfortunately, Lenovo's BIOS does not allow disabling Turbo Boost. ↩