Understanding Our Cache and the Web Cache Deception Attack
About a month ago, security researcher Omer Gil published the details of an attack that he calls the Web Cache Deception attack. It works against sites that sit behind a reverse proxy (like Cloudflare) and are misconfigured in a particular way. Unfortunately, the definition of "misconfigured" for the purposes of this attack changes depending on how the cache works. In this post, we're going to explain the attack and then describe the algorithm that our cache uses to decide whether or not to cache a given piece of content so that customers can be sure that they are secure against this attack.
The Attack
First, we'll explain the basics of the Web Cache Deception attack. For those who want a more in-depth explanation, Omer's original post is a great resource.
 CC BY-SA 2.0 image by shelleygibb
CC BY-SA 2.0 image by shelleygibb
Imagine that you run the social media website example.com, and that each of your users has a newsfeed at example.com/newsfeed. When a user navigates to their newsfeed, the HTTP request generated by their browser might look something like this:
GET /newsfeed HTTP/1.1
Host: example.com
...
If you use Cloudflare, you don't want us to cache this request because if we did, some of your users might start seeing other users' newsfeeds instead of their own, which would be very bad. Luckily, as we'll explain below, this request won't be cached because the path in the request (the /newsfeed part) doesn't have a "cacheable file extension" (a file extension such as .jpg or .css that instructs Cloudflare that it's OK to cache the request).
The trouble begins if your website is configured to be flexible about what kinds of paths it can handle. In particular, the issue arises when requests to a path that doesn't exist (say, /x/y/z) are treated as equivalent to requests to a parent path that does exist (say, /x). For example, what happens if you get a request for the nonexistent path /newsfeed/foo? Depending on how your website is configured, it might just treat such a request as equivalent to a request to /newsfeed. For example, if you're running the Django web framework, the following configuration would do just that because the regular expression ^newsfeed/ matches both newsfeed/ and newsfeed/foo (Django routes omit the leading /):
from django.conf.urls import url
patterns = [url(r'^newsfeed/', ...)]
And here's where the problem lies. If your website does this, then a request to /newsfeed/foo.jpg will be treated as the same as a request to /newsfeed. But Cloudflare, seeing the .jpg file extension, will think that it's OK to cache this request.
Now, you might be thinking, "So what? My website never has any links to /newsfeed/foo.jpg or anything like that." That's true, but that doesn't stop other people from trying to convince your users to visit paths like that. For example, an attacker could send this message to somebody:
Hey, check out this cool link! https://example.com/newsfeed/foo.jpg
{kind=link}
If the recipient of the message clicks on the link, they will be taken to their newsfeed. But when the request passes through Cloudflare, since the path ends in .jpg, we will cache it. Then the attacker can visit the same URL themselves and their request will be served from our cache, exposing your user's sensitive content.
Defending Against the Web Cache Deception Attack
The best way to defend against this attack is to ensure that your website isn't so permissive, and never treats requests to nonexistent paths (say, /x/y/z) as equivalent to requests to valid parent paths (say, /x). In the example above, that would mean that requests to /newsfeed/foo or /newsfeed/foo.jpg wouldn't be treated as equivalent to requests to /newsfeed, but would instead result in some kind of error or a redirect to a legitimate page. If we wanted to modify the Django example from above, we could add a $ to the end of the regular expression to ensure only exact matches (in this case, a request to /newsfeed/foo will result in a 404):
from django.conf.urls import url
patterns = [url(r'^newsfeed/$', ...)]
We provide many settings that allow you to customize the way our cache will treat requests to your website. For example, if you have a Page Rule enabled for /newsfeed with the Cache Everything setting enabled (it's off by default), then we'll cache requests to /newsfeed, which could be bad. Thus, the best way to ensure that your website is secure is to understand the rules that our cache uses to determine whether or not a request should be cached.
How Our Cache Works
When a request comes in to our network, we perform two phases of processing in order to determine whether or not to cache the origin's response to that request:
- In the eligibility phase, which is performed when a request first reaches our edge, we inspect the request to determine whether it should be eligible for caching. If we determine that it is not eligible, then we will not cache it. If we determine that it is eligible, then we proceed to a second disqualification phase.
- In the disqualification phase, which is performed after we've received a response from the origin web server, we inspect the response to determine whether any characteristics disqualify the response from being cached. If nothing disqualifies it, then the response will be cached.
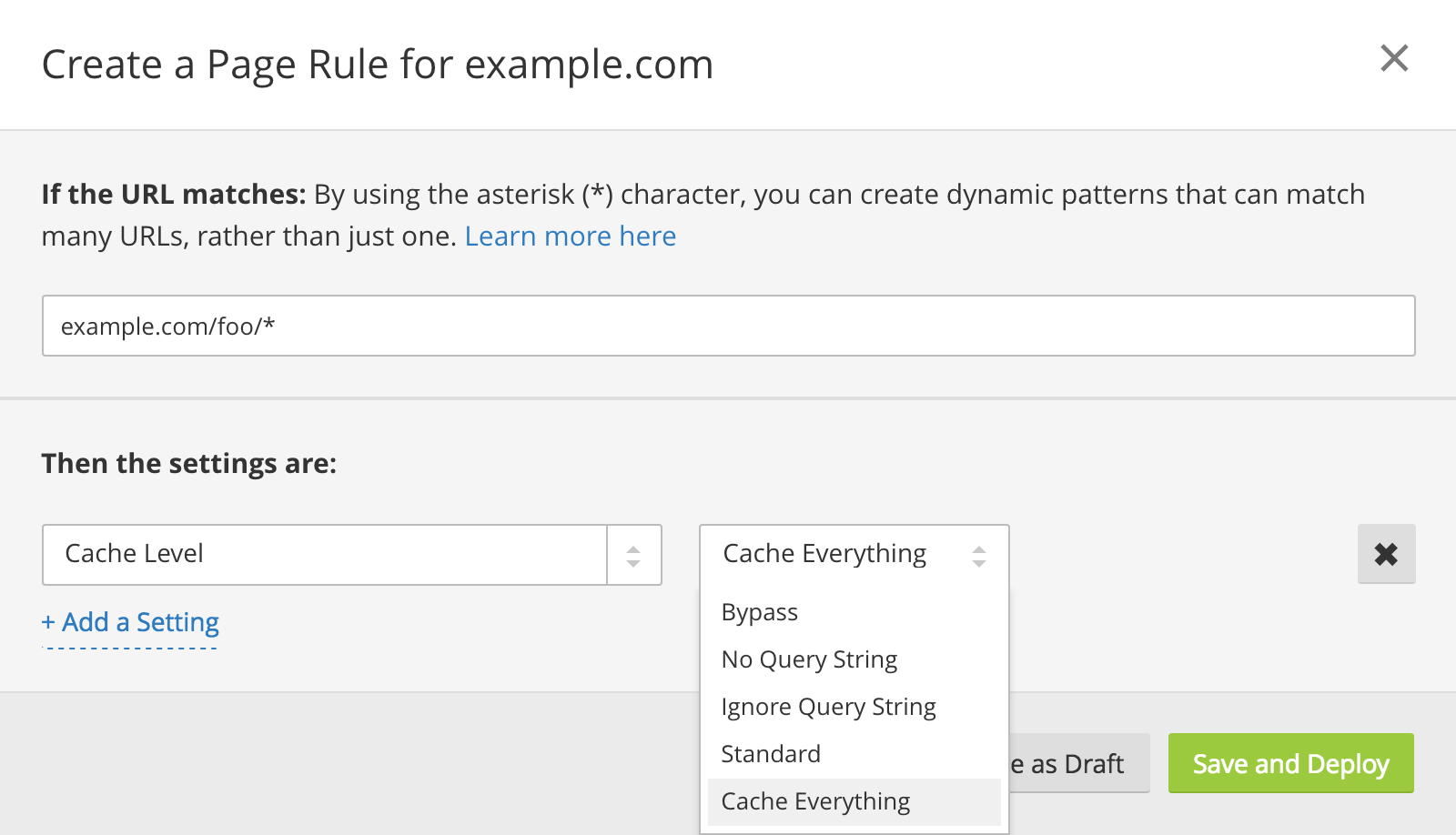 Configuring caching via a Page Rule
Configuring caching via a Page Rule
Note that site-wide settings or Page Rules can affect this logic. Below, when we say "a setting applies" or "the setting is," we mean that either a global setting exists which applies to all requests or a Page Rule with the setting exists that applies to the given request (e.g., a Page Rule for /foo/*applies to requests to /foo/bar, /foo/baz, /foo/bar/baz, etc). Page Rules override global rules if both apply to a given request.
Eligibility Phase
In the eligibility phase, we use characteristics of the request from the client to determine whether or not the request is eligible to be cached. If the request is not eligible, then it will not be cached. If the request is eligible, then we will perform more processing later in the disqualification phase.
The rules for eligibility are as follows:
- If the setting is Standard, Ignore Query String, or No Query String, then:
- a request is eligible to be cached if the requested path ends in one of the file extensions listed in Figure 1 below
- a request may be eligible to be cached (depending on performance-related decisions made by our edge) if the requested path ends in one of the file extensions listed in Figure 2 below
- a request is eligible to be cached if the request path is
/robots.txt
- If the setting is Cache Everything, then all requests are eligible to be cached.
In addition to the above rules, if either of the following two conditions hold, then any decision made so far about eligibility will be overridden, and the request will not be eligible to be cached:
- If the Cache on Cookie setting is enabled and the configured cookie is not present in a
Cookieheader, then the request is not eligible to be cached. - If the Bypass Cache on Cookie setting is enabled and the configured cookie is present in a
Cookieheader, then the request is not eligible to be cached.
Disqualification Phase
In the disqualification phase, which only occurs if a request has been marked as eligible, characteristics of the response from the origin web server can disqualify a request. If a request is disqualified, then the response will not be cached. If a request is not disqualified, then the response will be cached.
The rules for disqualification are as follows:
- If the setting is Standard, Ignore Query String, or No Query String, or if the setting is Cache Everything and no Edge Cache TTL is present, then:
- A
Cache-Controlheader in the response from the origin with any of the following values will disqualify a request, causing it not to be cached:no-cachemax-age=0privateno-store
- An
Expiresheader in the response from the origin indicating any time in the past will disqualify a request, causing it not to be cached.
- A
- If the setting is Cache Everything and an Edge Cache TTL is present, then a request will never be disqualified under any circumstances, and will always be cached.
There is one further set of rules relating to the Set-Cookie header. The following rules only apply if a Set-Cookie header is present:
- If the setting is Standard, Ignore Query String, or No Query String, or if the setting is Cache Everything and an Edge Cache TTL is present, then the request will not be disqualified, but the
Set-Cookieheader will be stripped from the version of the response stored in our cache. - If the setting is Cache Everything and no Edge Cache TTL is present, then the request will be disqualified, and it will not be cached. The
Set-Cookieheader will be stripped from the response that is sent to the client making the request.
class
css
jar
js
jpg
jpeg
gif
ico
png
bmp
pict
csv
doc
docx
xls
xlsx
ps
pdf
pls
ppt
pptx
tif
tiff
ttf
otf
webp
woff
woff2
svg
svgz
eot
eps
ejs
swf
torrent
midi
mid
Figure 1: Always Cacheable File Extensions
mp3
mp4
mp4v
mpg
mpeg
mov
mkv
flv
webm
wmv
avi
ogg
m4a
wav
aac
ogv
zip
sit
tar
7z
rar
rpm
deb
dmg
iso
img
msi
msp
msm
bin
exe
dll
ra
mka
ts
m4v
asf
mk3d
rm
swf
Figure 2: Sometimes Cacheable File Extensions
So there you have it. So long as you make sure to follow the advice above, and make sure that your site plays nicely with our cache, you should be secure against the Web Cache Deception attack.