Padding oracles and the decline of CBC-mode cipher suites
At CloudFlare, we’re committed to making sure the encrypted web is available to everyone, even those with older browsers. At the same time, we want to make sure that as many people as possible are using the most modern and secure encryption available to them. Improving the cryptography used by the majority requires a coordinated effort between the organizations building web browsers and API clients and those working on web services like CloudFlare. Cryptography is a two-way street. Even if we support the most secure cryptographic algorithms for our customers, web visitors won’t get the benefit unless their web client supports the same algorithms.
In this blog post we explore the history of one widely used cryptographic mode that continues to cause problems: cipher block chaining (CBC). We’ll explain why CBC has proven difficult to use safely, and how recent trends in the adoption of secure ciphers by web clients have helped reduce the web’s reliance on this technology. From CloudFlare’s own data, we’ve seen the percentage of web clients that support safer cipher modes (such as AEAD) rise from under 50% to over 70% in six months, a good sign for the Internet.
What’s in a block cipher?
Ciphers are usually grouped into two categories: stream ciphers and block ciphers. Stream ciphers encrypt data on a byte-by-byte basis. Plaintext and ciphertext are always the same length. Examples of pure stream ciphers are RC4 and ChaCha20. Although RC4 is no longer considered secure, we can still rely on ChaCha20 as a secure stream cipher for use on the web, but it was only recently standardized by the IETF and therefore does not have broad adoption.
Unlike stream ciphers, which can encrypt data of any size, block ciphers can only encrypt data in "blocks" of a fixed size. Examples of block ciphers are DES (8-byte blocks) and AES (16-byte blocks). To encrypt data that is less than one block long using a block cipher, you have several options. You can either turn the block cipher into a stream cipher (using something called counter mode, more on this later), or you can include extra bytes as padding to align the data to the block size. If the data is longer than one block, then the data needs to be split into multiple blocks that are encrypted separately. This splitting process is where things get tricky.
The naïve approach to encrypting data larger than the block size is called Electronic Code Book (ECB) mode. In ECB mode, you split your data into chunks that match the cipher’s block size and then encrypt each block with the same key. ECB turns out to be a very bad way to encrypt most kinds of data: if the data you are encrypting has redundant portions, say an image with many pixels of the same color, you end up with the "Tux" problem (demonstrated below). If two blocks have the same value, they will be encrypted to the same value. This property lets an attacker know which plaintext blocks match by looking at the ciphertext blocks.
For example, here’s what a high-resolution version of Linux’s "Tux" looks when encrypted in ECB mode:


Image from Filippo Valsorda’s blog
The fact that identical plaintext blocks are encrypted to identical ciphertext blocks gives an unwanted structure to encrypted data that reveals information about the plaintext.
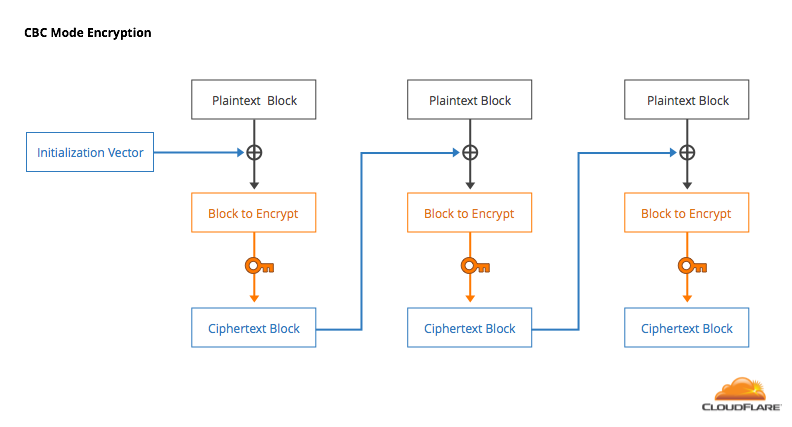
One solution to this is to "chain" blocks together by taking the output of one encryption and mixing it into the input for the next block. There are several block cipher modes, but the one that was originally standardized in SSL (and continues to be used in TLS) is Cipher Block Chaining (CBC). In CBC, the plaintext of one block is combined with the ciphertext of the previous block using the exclusive OR operation (XOR). The first block is XOR’d with a randomly generated initialization vector (IV).
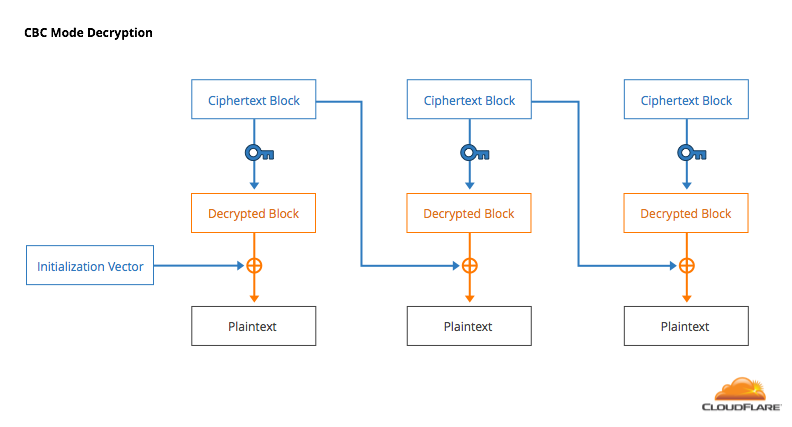
Decryption works by XORing the previous block of ciphertext (or the IV) into the output of the decryption.
CBC has some nice properties. The ciphertext produced by a block cipher is encrypted, so it (hopefully) looks random. In CBC, you’re mixing this random looking encrypted data into the plaintext, making it very unlikely that there will be patterns in the output. Another advantage is that decryption can be done in parallel to speed things up. However, CBC has proven to be more trouble than expected when used in the context of the HTTPS and the web.
How records are encrypted in TLS
TLS provides both encryption—via a cipher—and integrity—via a message authentication code (MAC). When SSL was originally designed, one open question was: should we authenticate the plaintext data, or should we encrypt and then authenticate the encrypted data? This is sometimes stated as MAC-then-encrypt or encrypt-then-MAC? They chose MAC-then-encrypt (encrypt the authenticated data) which has since proven to be the less than ideal choice.
In cryptographic protocol design, leaving some bytes unauthenticated can lead to unexpected weaknesses (this is known as the Cryptographic Doom Principle). When encrypting data using a block cipher mode like CBC, the last block needs to be padded with extra bytes to align the data to the block size. In TLS, this padding comes after the MAC. (There is a TLS extension, described in RFC 7366, that enables encrypt-then-MAC, but it’s rarely implemented.)
A TLS record has the following format. Each one has an 8-byte sequence number that is stored and incremented on each new one. The encrypted part of a request needs to add up to a multiple of 16 bytes, but for the purposes of this post, let’s assume that this length is 64 bytes (4 blocks).
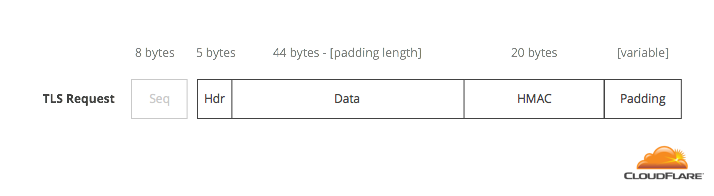
In TLS, valid padding looks like a number preceded by that number of copies of itself. So, if the number is 0x00, it’s repeated 0 times:
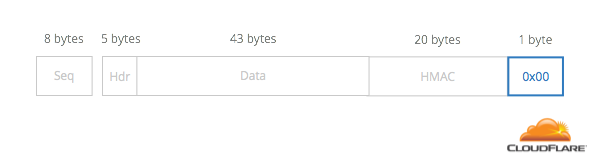
If the number is 0x02, it’s repeated 0x02 times:

To decode a block, decrypt the entire message, look at the last byte, remove it, and remove that many bytes of padding. This gives you the location of the HMAC.
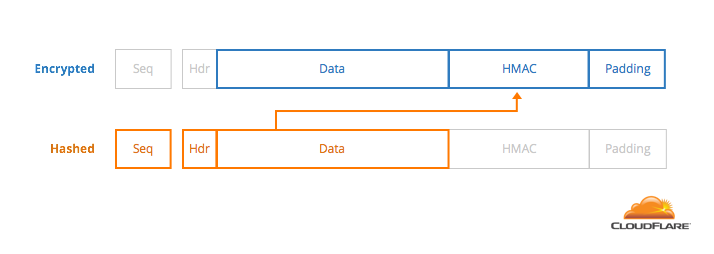
To compute the MAC, take the sequence number, the 5-byte header, and the message, then HMAC them using the shared integrity key.
Padding oracle
The problem with this construction is that it is susceptible to a technique called the padding oracle attack. This attack was first reported against TLS by Serge Vaudenay in 2002. A padding oracle is a way for an attacker with the ability to modify ciphertext sent to a server to extract the value of the plaintext.
Attackers don’t have to be an ISP or a government to get in the middle of requests. If they are on the same local network as their victim they can use a technique called ARP spoofing. By tricking the victim’s machine to forward data to the attacker’s machine instead of the router, they can read, modify and measure the time it takes for every encrypted message sent from the browser to the server. By injecting JavaScript into an unencrypted website the client is visiting, they can get the browser to repeatedly send requests to a target HTTPS site. These requests contain valuable data such as login cookies and CSRF tokens.
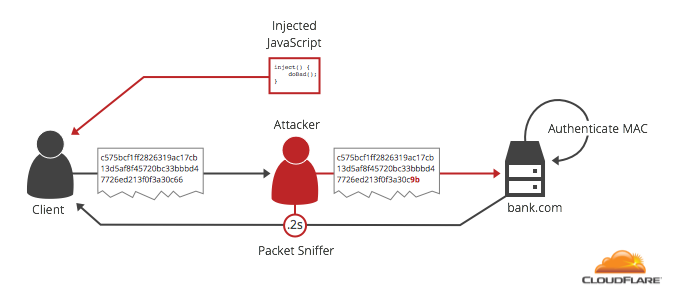
If the TLS server behaves differently when decrypting ciphertext that has correct padding vs. incorrect padding, the attacker can carefully craft ciphertexts that provide enough information to reveal the plaintext data.
This kind of sounds like magic, but it really isn’t. Given a ciphertext, there are three possible ways for the *decrypted data *to look:
Invalid padding
Valid padding, wrong HMAC
Valid padding, correct HMAC
Originally, the TLS server would return a different error code for cases 1 and 2. Using the structure of CBC, an attacker can construct 256 ciphertexts whose last bytes decrypt to the numbers 0x00 to 0xFF. By looking at the error code, the attacker can tell which one of those ciphertexts decrypted to the value 0x00, a valid 0-byte padding.
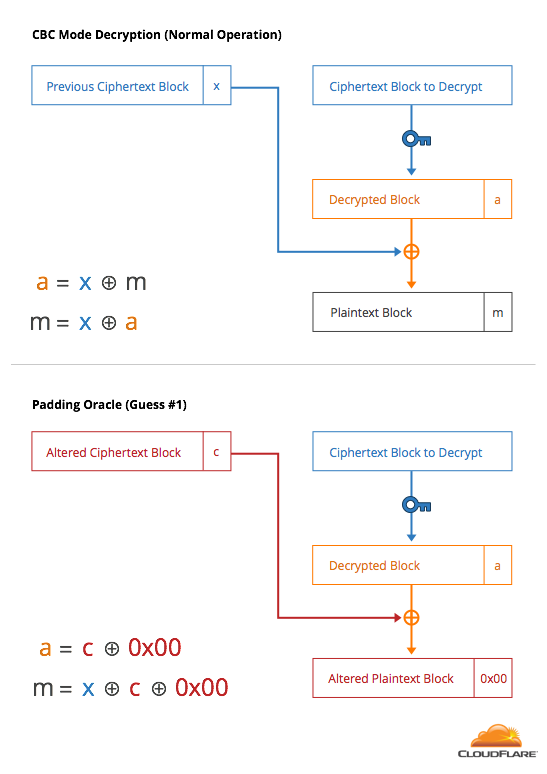
With that knowledge, the attacker can then construct 256 guesses where the last byte is 0x01 and the second-to-last byte covers 0-255. The error code lets the attacker know which one decrypts to 0x01, causing the last two bytes to be 0x01 0x01, another valid padding. This process can be continued to decrypt the entire message.
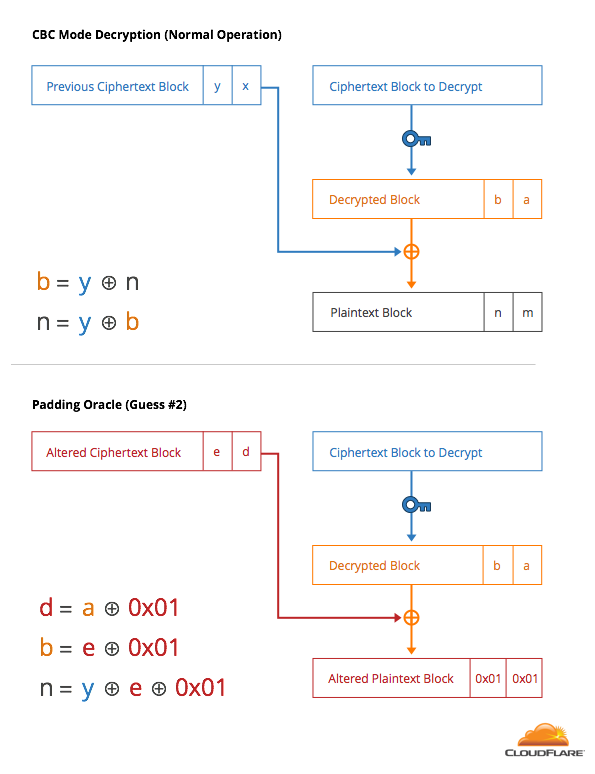
The fact that the padding is unauthenticated and that an attacker can tell the difference between a correct and incorrect guess makes this attack very powerful. This error code provides a tiny bit of information about the plaintext to the attacker for each decryption. This is what’s called a side-channel, information leakage that is visible to a third party.
The original Vaudenay attack was mitigated by returning the same error code for both cases 1 and 2; however, the attack was revived again using another side channel: timing.
Consider the amount of work a server has to do in each of these cases:
Invalid padding – Read the padding bytes
Valid padding, wrong HMAC – Read the padding bytes, compute the HMAC
Valid padding, correct HMAC – Read the padding bytes, compute the HMAC
In Vaudenay’s original attack, the error code gave away the difference between scenarios 1 and 2. In the timing version of the padding oracle, the attacker measures how much time it takes for the server to respond. A fast response means scenario 1 and slow responses mean scenario 2 or 3. Timing attacks are subject to some jitter due to the fact that computers are complex and sometimes requests just take longer than others. However, given enough attempts you can use statistics to determine which case you are in. Once the attacker has this oracle, the full plaintext can be decrypted using the same steps as the original Vaudenay attack described above.
To fix the timing attack, TLS implementations were changed to perform the HMAC even if the padding is invalid. Now every time invalid padding is found in a decrypted ciphertext, the server would assume zero padding and perform a dummy HMAC on all data. The amount of time spent should be constant for cases 1, 2 and 3. Or so we thought.
Getting lucky
As it turns out, it’s very difficult to find a heuristic that takes a branching program and making all branches take the same amount of time. In 2013, Nadhem AlFardan and Kenny Paterson found that there was still a timing oracle in TLS, based on the fact that HMAC takes a different amount of time to compute based on how much data is being MAC’d. They called their attack Lucky 13.
What makes Lucky 13 possible is the fact that an HMAC of 55 bytes takes less time than an HMAC of 56 bytes, and 55 - 13 (of extra data) + 20 (of MAC) = 62, which is… luckily close to a block size multiple (64). This can be exploited to give a small timing difference that can be used as a decryption oracle.
Say the decryption is 64-bytes long (4 AES blocks), then the data can look like:
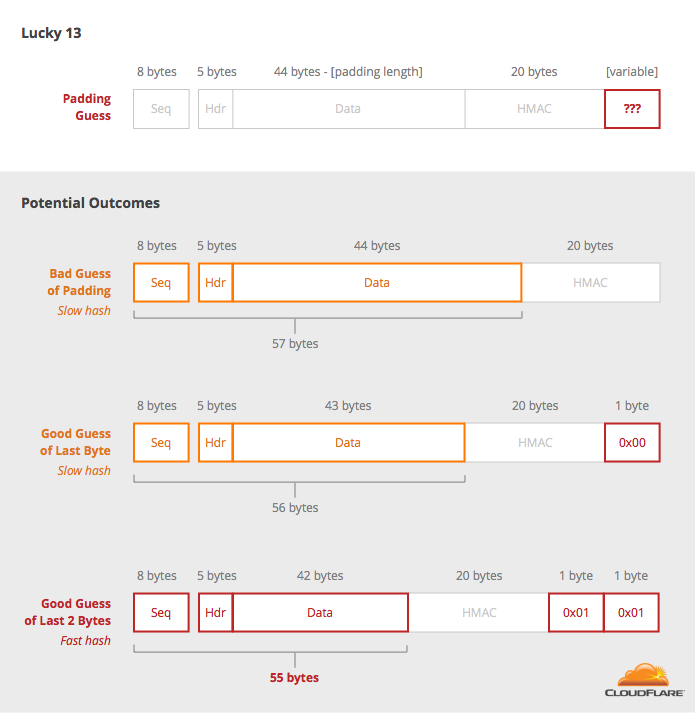
By picking every combination of the last two bytes, you can identify which pair of values result in the padding 0x01 0x01, which can be identified by a slightly faster operation on the server. With this information in hand, you can jump ahead to step 2 of the padding oracle. Guessing two bytes at once takes more guesses (around 216 = 65536 rather than 256 for one guess), but it is still practical.
The fact that the sequence number and header together are 13 bytes long enable this attack to work and inspired the name "Lucky 13". The authors note how if it were only 12 bytes then they wouldn’t need to guess the last two bytes at once, making it even faster.
"In some sense, 13 is lucky, but 12 would have been luckier!" - AlFardan & Paterson
Lucky 13 can be mitigated by making sure HMAC takes the same amount of time no matter how much data goes into it. The code to make the HMAC constant time was so complicated and difficult to implement that it took several attempts to fix. Other implementers ran into similar problems mitigating Lucky 13. In 2015, Paterson and Albrecht found that Amazon’s TLS implementation (called s2n) was also susceptible to a variant of the attack despite attempts to mitigate it in the code, due to an even more obscure pattern in HMAC timing. Other libraries haven’t yet implemented a fix. For example, Golang’s crypto package is still susceptible to Lucky 13 (CloudFlare’s own Filippo Valsorda has proposed a fix, but is has yet to be reviewed by the language maintainers). Timing oracles are extremely hard to avoid when implementing CBC ciphers in MAC-then-encrypt mode.
As soon as the Lucky 13 paper was released, CloudFlare adopted OpenSSL’s server-side fix. This helps prevent visitors to sites on CloudFlare from being affected by Lucky 13 when they use CBC mode, however the preferred solution would be to move to a cipher mode that is not susceptible to this kind of attack.
What to use if not CBC?
Timing oracles are not the only vulnerabilities that CBC mode ciphers suffer from. Both BEAST and POODLE were high-profile TLS vulnerabilities that only affected CBC mode ciphers. There are still valid uses of CBC mode (such as for encrypting static content), but in the context of TLS, MAC-then-encrypt with CBC has had too many issues to be ignored.
The attacks on RC4 and CBC have left us with very few choices for cryptographic algorithms that are safe from attack in the context of TLS. In fact, there are no ciphers supported by TLS 1.1 or earlier that are safe. The only options are CBC mode ciphers or RC4. In TLS 1.2, a new cipher construction was introduced called AEAD (Authenticated Encryption with Associated Data). AEAD takes a stream cipher and mixes in the authentication step along the way rather than computing the MAC at the end. CloudFlare implements two such cipher modes, AES-GCM and ChaCha20-Poly1305. ChaCha20 is a stream cipher, and Poly1305 a MAC scheme. AES-GCM instead uses counter mode to turn the block cipher AES into a stream cipher and adds authentication using a construction called GMAC.
Since communication requires two parties, both the web client and web server need to support the same ciphers and cipher modes. Luckily, adoption of AEAD cipher modes in clients is growing.
Client support for AEAD cipher modes
Most modern browsers and operating systems have adopted at least one AEAD cipher suite in their TLS software. The most popular is AES-GCM, however some browsers (Google Chrome in particular) support both AES-GCM and ChaCha20-Poly1305. Until late 2015, the major exception to this rule was Apple, whose iOS and Mac OS X operating systems only supported AES in CBC mode and never supported ChaCha20-Poly1305, making both Safari and iOS Apps susceptible to Lucky 13.
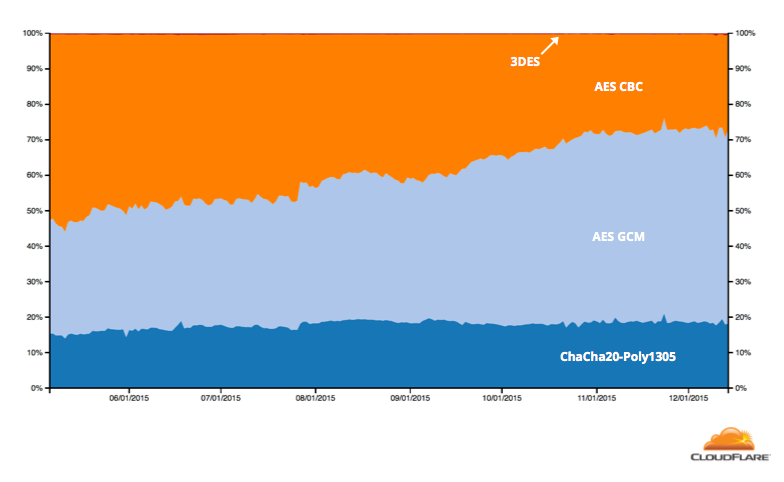
The following graph shows the ciphersuites negotiated between web clients and sites using CloudFlare over the last six months of 2015. Both iOS 9 and Mac OS 10.11 were released in September 2015, helping push the percentage of AEAD ciphers used in connections to CloudFlare over 60%. The increased adoption of modern versions of Microsoft’s Edge browser has also contributed to the growth.
Conclusions
Even the most well-intentioned cryptographic constructions can turn out to cause more problems than they’re worth. This is what happened with CBC-mode block ciphers over the years as more problems with MAC-then-Encrypt were discovered. The cryptographic community is constantly working on new algorithms, but only those with the most vetting end up making it to mainstream protocols like TLS. In choosing cryptographic algorithms for an ecosystem like the web, it’s best to follow the advice of standards bodies like the IETF and implement what works and is secure.
As a company that provides HTTPS for a large portion of the Internet, it’s our responsibility to keep our customers secure by implementing the latest standards, like AEAD cipher suites. We have a team of talented cryptographers who stay on pulse of things, and are able to handle everything from 0-day vulnerabilities to adherence to latest standards to keep customers safe. However, keeping servers up to date is only half of the equation. Web clients also need to keep up to date, and web users need to keep using the latest browsers. The good news is that our data shows that web clients are rapidly moving toward secure AEAD-based ciphers, but we still have a long way to go to keep everyone secure.